The difference between NSA’s “PRISM” and “Upstream” surveillance -- a technical explanation
Introduction
It was one of the first Snowden bombshell stories, the alleged “direct access” under PRISM. The claim was mainly concluded from this slide:

I was one of those who were skeptical from the very beginning. Technically unskilled people may interpret “collection directly from the servers” would mean that the NSA directly collects from the servers (Snowden and his supporters maintain until today that the misinterpretation happened because the NSA had claimed a “direct access” in their slides) -- but this is simply not correct. The NSA’s wording is correct, and it doesn’t mean a “direct access” -- the aim of the slide is to explain the difference between PRISM and Upstream, the difference between collections from servers and network taps. In the following I will explain the technical details, and what this means, both for intelligence importance and privacy implications. And after having read it, you will understand that the key point of the slide is “You Should Use Both”, not “collection directly”. PRISM has advantages and disadvantages, as well as Upstream -- and both regarding intelligence gathering and privacy implications.
To know about this technical basics is crucial for other related topics as well, like for example the “bulk collection” vs. “mass surveillance” discussion related to the “EU-U.S. Privacy Shield” framework.
As a last introduction, I will use email as an example for the technical explanations. Both PRISM and Upstream affect other internet services too, but email is one of the most complex with likely the most privacy implications, so it is for sure the best choice to use as example.
PRISM Surveillance
Let’s first look at PRISM, because this is the easier part. Under PRISM, the NSA collects data that is stored on the servers of American internet companies, like Google or Facebook. So, if for example the NSA targets the email account “badguy@gmail.com”, they make a formal request to Google, and Google in return hands over all emails from and to this account.
For NSA analysts, this kind of collection has several advantages and disadvantages.
Advantages of PRISM collection
The emails are collected in cleartext (unless an end-to-end encryption like PGP or GPG was used).
The emails are complete, which means that all emails to and from the target are collected. So if you imagine the NSA targets “badguy@gmail.com”, they will collect all emails to and from this address, because they all necessarily go through Google servers.
Disadvantages of PRISM collection
Only email accounts on American email servers can be targeted (eg “putin@mail.ru” can not be targeted at all, emails to or from this address could only be collected “incidentally” if emails to or from “putin@mail.ru” are sent to or from another PRISM target, but not if they are sent to or from an unrelated account on a “PRISM company” (*).
Emails where both the sender’s and recipient’s email server is outside the USA can not be collected at all (eg no chance to collect emails from “badguy@gmx.de” to “putin@mail.ru”).
Upstream Surveillance
Upstream collection is much more complicated, and you need a pretty good technical knowledge to really understand how it works, to know about the benefits and limitations.
So let’s start with a little diagram depicting how data is transmitted between two email servers over the internet:
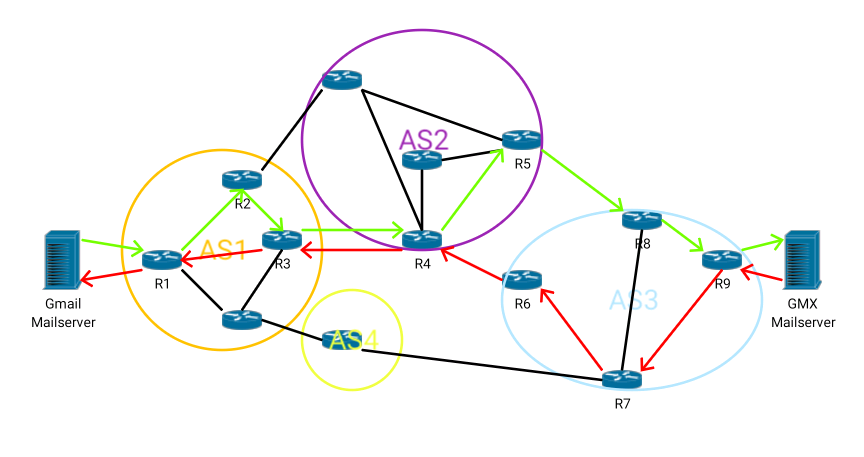
The picture maybe a bit confusing at first sight -- I’m sorry, I told you it’s a bit more complicated --, but let me explain: The internet is basically a big net of interconnected routers (R1, R2, …). It is more or less a mess how they are interconnected. And the routers belong to so-called “Autonomous Systems” (AS1, AS2, …). An autonomous system is mostly a company, an internet carrier, like for example AT&T or Deutsche Telekom.
The next you need to know is a bit about internet routing, and here two points are important: It is dynamic and often asymmetric. Dynamic means that if a link between routers or a router itself fails then internet routing protocols will look for another way. However, as long as nothing happens, the routing is usually stable, which means it is very unlikely that a “path” from source to destination changes during a transaction.
The second important thing is asymmetric routing. For an illustration look again at the drawing: Data from the Gmail to the GMX email server follows the green path, while data from GMX to Gmail goes the red one (as a side note, in my example only the “router path” is asymmetric, but not the “AS path”; this is coincidence, imagine the path from GMX to Gmail would go through AS4, then this would be asymmetric too).
So what does this mean? If you have, for example, access to router R3 or R4, or to the uplink between R3 and R4, then you can collect emails from Gmail to GMX and vice versa. If you have access to R5, you can only collect emails from Gmail to GMX, and on R7 only from GMX to Gmail. If you only have access to one of the untitled routers, you cannot collect any emails between Gmail and GMX.
One note about international routing: The internet is per definition global. The routers don’t know about national borders. If you send an email from New York City to Washington D.C., it could theoretically be routed over London, Amsterdam, Frankfurt, Moscow, Shanghai, Tokyo and Los Angeles. But this is usually not the case. Long ways mean long delays and thus poor user experience, most serious providers try to avoid this. And it is mostly much easier to agree to domestic peering than to international. So in praxis, at least in developed countries like the U.S. or Germany, domestic traffic will almost always remain inside the country.
This is basically all you need to know about internet routing to understand the following explanations and conclusions. But please keep in mind that the internet backbone is much bigger as my picture, it consists of tenth of thousands of autonomous systems and hundreds of thousands of routers.
Let’s look at the “advantages” and “disadvantages” of Upstream collection, and here let's start with the “disadvantages”:
Disadvantages of Upstream collection
One of the most important disadvantages of Upstream collection, compared to PRISM collection, is (possible) encryption. If the communication is encrypted, it can be hard or even impossible for the NSA to read the intercepted data (**), and even collected metadata is often useless (***).
And here it is important to understand that Snowden was kind of a game changer. Encryption was available long before Snowden, but it was mostly only used for financial or business uses, but not for transmission of personal data. But this changed dramatically after Snowden, now Facebook, the Google search engine, almost all Webmailer, and so on, use encrypted HTTPS as default or even the only option. And most email servers now support STARTTLS -- so while before Snowden very little emails were transmitted encrypted, today almost all emails are. This is a very important point for the overall understanding, I’ll come back to it in the conclusions.
Another disadvantage is that the collection is likely not complete, compared to PRISM collection. Let’s take for example again the NSA targets “badguy@gmail.com”, and then recapitulate the picture above about the “messy” internet with its hundreds of thousands of uplinks of which you can safely assume that thousands of them are crossing U.S. borders. This means that the NSA could only get a complete collection if they were able to intercept (or have intercepted) all of these uplinks. And this is hardly imaginable, let me shortly explain why:
First, I don’t want to underestimate the NSA’s Upstream collection capabilities. I rather think it’s quite mighty, and I think (I say “think” because we know little for sure here, neither the “Snowden documents” nor declassified government documents draw a clear picture so far) this is mostly related to the fact that the NSA doesn’t directly tap internet uplinks under Upstream. They just compel American carriers to hand over data matching to specific selectors, and I think the NSA doesn’t have to specify specific uplinks to be taped. So my assumption so far is that the NSA can, for example, go to AT&T and demand: ‘Give me all traffic on all of your international uplinks matching to “badguy@gmail.com”’. So far, so good for the NSA, but this will hardly be all traffic. First, because the NSA has to trust these companies, because they need to give them their selectors, and the selectors clearly show what the NSA is interested in -- I can hardly imagine the NSA trusts all American companies that they keep this secret, let alone foreign companies running international uplinks terminating in the U.S. And second because the carrier market is quite dynamic, companies come and go, uplinks are launched and released -- it is hardly imaginable all of these carriers get instant NSA collection directives.
Just another disadvantage of Upstream is that the data is volatile. It is sent usually only once over the wire, and if the NSA is not able to tap it right then, it’s lost forever -- contrary to PRISM where the data is as long on the servers until it is deleted.
So, roughly spoken, Upstream collection depends quite a lot on coincidence. Look at the diagram and the asymmetric routing, it is possible emails from “badguy@gmail.com” to “putin@mail.ru” are collected, but not the answers. Or vice versa. Or nothing is collected because the data is sent over non-PRISM carriers. Or there was a temporary routing problem. Or or or …
Advantages of Upstream collection
A big advantage of Upstream collection is that it is possible to target everyone, not only accounts related to U.S. companies. So it is not possible to target “putin@mail.ru” under PRISM, but it is possible with Upstream.
Another advantage is related: Find new targets.
Let’s take for example again that the NSA is interested in “putin@mail.ru”. It is impossible to target this account under PRISM, because it is not run by an American internet company. But the NSA can target “putin@mail.ru” under Upstream, and with that they may learn that “putin@mail.ru” communicates a lot with “badguy@gmail.com” -- and according to this information they may target “badguy@gmail.com” under PRISM.
A third advantage is something we learned from the PCLOB 702 report, that with Upstream it is possible to collect communications that are “about” a target, not only “to” or “from” it. A good example for this is: Imagine “hollande@mail.fr” received an email from “putin@mail.ru” and then he forwards this email to “merkel@gmail.com”. Neither “hollande@mail.fr” nor “merkel@gmail.com” are NSA targets, but “putin@mail.ru” is, so it is possible to collect this email -- imposible with PRISM.
Conclusions
One aim was to point out Snowden's (and his supporters) confusion about “his” documents. It was the first time (but by far not the last time) that Snowden clearly showed that he lacks basic technical knowledge that is necessary to understand “his” documents. And I have little confidence that he has this technical knowledge today. But I hope at least you, the reader, now understand that the slide above doesn’t claim a “direct access”, that instead the key point of the slide is “You Should Use Both”, and that this is because there are big differences between PRISM and Upstream collections, with advantages and disadvantages, and that a good NSA analyst knows about these differences and uses both PRISM and Upstream in a smart way.
Another conclusion is that Upstream collection today is most likely pretty useless for NSA surveillance, simply because the use of encryption heavily increased after Snowden (and yes, this is one of the few good Snowden effects; even when it may hurt legitimate NSA surveillance, but sensitive data should never be transmitted unencrypted, at least not over public media like the internet).
My third conclusion is that we should consider the internet again as a public medium. When I started to work as an internet technician in the 90s, one of the first thing I was teached was: The internet is an untrustworthy medium, packets may travel all over the globe, with possible access of various technicians, companies and nation states, so don’t expect any privacy, encrypt all sensitive data. And this is just another difference between PRISM and Upstream: PRISM collections (like a Gmail mailbox) are associated with much more privacy implications than Upstream collection, because users can expect privacy for their Gmail mailbox, which they can’t expect for data transmitted unencrypted over the internet.
(*) There is no technical reason for this “limitation”, Google or other American internet companies could search all emails on their servers for “putin@mail.ru”. But there is obvious no legal base for the NSA to demand this, and the PCLOB 702 report makes it clear it is not done.
(**) It is possible that a weak encryption or implementation is used, but even then the decryption is almost always very hard and time-consuming; and it is often possible to decrypt the data with a so-called “man-in-the-middle” attack, but this is an active attack that alters the communication, thus high risk of detection, so will likely not work on large scale; and it is often possible to alter the communication in a way that it falls back to unencrypted, but like the “man-in-the-middle” attack this is a high risk active attack that will likely not work on large scale.
(***) For example, if Gmail and GMX use STARTTLS to transmit emails encrypted, and such an email transfer is intercepted, all the eavesdropper sees is that some Gmail-user sent an email to some GMX-user, but not which users exactly, and no other useful information.
Keine Kommentare:
Kommentar veröffentlichen